Data Engineer Interview Question
A Test-Driven Development approach to solving a data processing problem given in an interview take-home assessment.
August 1, 2022
Python
|
Data Processing

The Problem
In a recent engineering interview I was given the following take-home assessment problem:
- You are given a CSV file with two columns of integers as strings.
- The first column has the numbers 1:1000000, unordered, with one value missing.
- The second column is the same but with a different order and two values missing.
- First, find the number that is missing from both columns.
- Then, find the number missing in the first column.
The provided CSV file looks as follows:
"359803","583035"
"357353",""
"633834","523049"
"453111","701564"
"","829488"
"598043","416142"
"709298","914973"
"865343","549521"
"183281","341882"
"404978","623801"
...
...
...
"787303","534748"
"260831","742456"
"436372",""
"825283","233817"
"205556","484274"
"243051","911476"
"84359","498681"
"181643","838601"
"454707","525760"
"205823","541473"
...
...
...
Initial Planning
My idea is to write a function in challenge.py that will take in the CSV filename as an argument and return the requested results in an array, as such:
"""challenge.py"""
from typing import List
def solution(csv_file: str) -> List[int]:
"""Given a headerless csv file
with two equal length columns of
integers in range 1 to (inf - 1) as
string literals, and empty string
literals in place of missing values,
returns an array of integers where the
first value is missing from both
columns and the second value is
missing from the first column.
Parameters
----------
arg1 : str
path/filename of csv file
Returns
-------
list of int
array containing int values missing from
both columns in input csv file
Example
-------
>>> from io import StringIO
>>> test_csv = StringIO('"3","4"\\n"1",""\\n"",""\\n"4","1"')
>>> solution(test_csv)
[2, 2]
"""
result = []
return result
The plan is to read the CSV file, sort each column, then loop a binary search algorithm over the second column to find the missing values. We can use those missing values to index the sorted first column and compare. Once we have the missing value shared between the columns, for the second part we can just perform a binary search on the first sorted column and obtain the single missing value.
We will achieve all of this by breaking the problem up into two smaller helper functions, one to read the CSV file and sort the values and one to find the missing values with a binary search, then calling these helper functions in our solution() function to get the requested results.
For reading and sorting the CSV file columns let’s write two separate functions that return the same result, one using the pandas library and one without, in case using a third party library was not allowed.
def _pd_read_and_sort(file_name: str) -> List[List[int]]:
"""Given a csv file containing unlabeled columns of
unique numbers as strings, returns an array containing
arrays of each column sorted in ascending order as
integers with any empty or missing elements replaced
with 0s in the first positions.
Parameters
----------
arg1 : str
path/filename of csv file
Returns
-------
list of list of int
array containing arrays of sorted int values
Example
--------
>>> from io import StringIO
>>> test_csv = StringIO('"1","4"\\n"",""\\n"3","6"')
>>> _pd_read_and_sort(test_csv)
[[0, 1, 3], [0, 4, 6]]
"""
return_columns = []
return return_columns
def _read_and_sort(file_name: str) -> List[List[int]]:
"""Given a csv file containing unlabeled columns of
unique numbers as strings, returns an array containing
arrays of each column sorted in ascending order as
integers with any empty or missing elements replaced
with 0 in the first positions.
Parameters
----------
arg1 : str
path/filename of csv file
Returns
-------
list of list of int
array containing arrays of sorted int values
Example
--------
>>> from io import StringIO
>>> test_csv = StringIO('"1","4"\\n"",""\\n"3","6"')
>>> _pd_read_and_sort(test_csv)
[[0, 1, 3], [0, 4, 6]]
"""
return_columns = []
return return_columns
Next we will create a function that will find the missing values from these sorted arrays.
def _missing_from_list(input_list: List[int]) -> List[int]:
"""Given an array of ascending sorted integers,
starting at the first non-zero integer, returns a
sorted array containing all missing sequential integers
from the input array using a looped binary search
algorithm.
Parameters
----------
arg1 : list of int
array of sorted int values
Returns
-------
list of int
array of sorted ints missing from the input array
Example
-------
>>> _missing_from_list([0, 0, 1, 2, 3, 5, 6, 8, 9])
[4, 7]
>>> _missing_from_list([1, 2, 3, 4, 5, 6, 7, 8, 9])
[]
"""
missing = []
return missing
Now that we have a plan for how we will solve this problem and an outline of the functions we will be using, we can write some tests for how these functions should handle and return data.
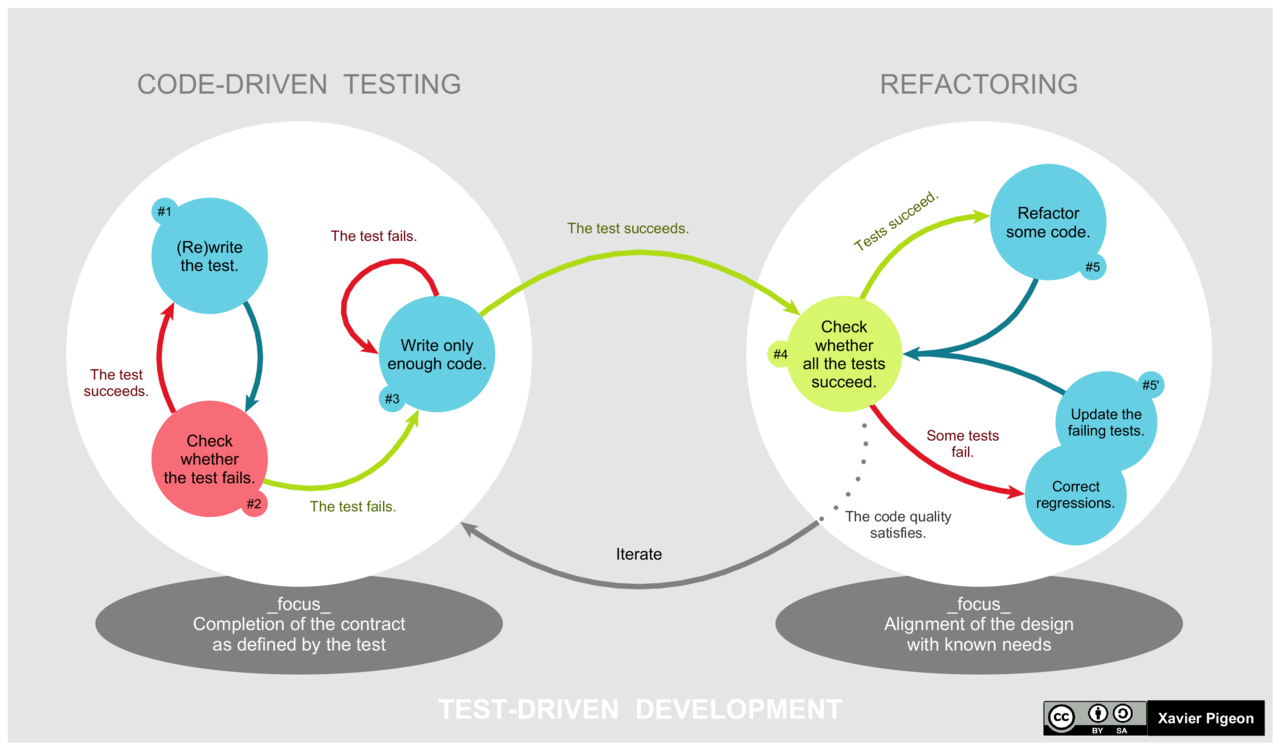
Testing and TDD
Test-Driven Development, or TDD, is a software development methodology where writing test cases is prioritized over the full development of software components in the development process. We cyclically run these tests anytime changes are made to the code. This allows us to clearly define requirements for our components before we begin to develop them, reduces the chance of introducing bugs during iterative development, refactoring, debugging and ensures our code will always behave as expected.
We will be using python’s unittest framework for our testing. The first thing we need to do is generate some data to test against. This data should be self-contained within our testing module as we do not want our tests to interact with the filesystem outside of the code that we are testing. We will use unittest’s mock library to achieve this.
Let’s write two helper functions, one to generate randomized arrays of sequential numbers, with selected values missing, and one to format these arrays into a string of newline separated “rows” to be used for our mock CSV file object.
"""test.py"""
import unittest
from unittest.mock import patch, mock_open
from typing import List
from random import sample, randint
from challenge import _pd_read_and_sort, _read_and_sort, _missing_from_list
from challenge import solution
def _generate_column(missing: List[int], length: int) -> List[int]:
"""Helper function to generate randomized array of
N length unique integers with 0 standing in for
missing integers.
Parameters
----------
arg1 : list of int
array of integers to exclude from returning array
Returns
-------
list of int
array containing unique integers
Example
-------
>>> test = _generate_column([2, 5], 10)
>>> len(test)
10
>>> sum(test)
48
"""
if not length:
return []
if missing:
missing.sort()
return_list = sample(range(1, missing[0]), (missing[0] - 1))
return_list += [0]
for i, num in enumerate(missing[:-1]):
return_list += sample(range(num + 1, missing[i + 1]),
(missing[i + 1] - (num + 1)))
return_list += [0]
return_list += sample(range(missing[-1] + 1, length + 1),
((length + 1) - (missing[-1] + 1)))
return return_list
def _write_to_csv_mock(first_column: List[int],
second_column: List[int]) -> str:
"""Helper function to write two arrays of integers
to mock csv file columns, substituting all 0 integers
with empty string literals.
Parameters
----------
arg1 : list of int
array of integers to write to first column
arg2 : list of int
array of integers to write to second column
Returns
-------
string
string of mocked csv data
Example
-------
>>> _write_to_csv_mock([1, 2, 3], [4, 5, 6])
'"1","4"\\n"2","5"\\n"3","6"\\n'
"""
return_data = ""
column_number = len(first_column)
for i in range(column_number):
one = "" if not first_column[i] else first_column[i]
two = "" if not second_column[i] else second_column[i]
return_data += f'"{one}","{two}"\n'
return return_data
Next let’s create our UnitTestModule class and build our testing data. This selection of data should cover most of the probable use cases our functions will encounter.
class UnitTestModule(unittest.TestCase):
"""Test all functionality for challenge module."""
# Generate and test all testing data
length = 1000000
# create two random integers to remove from lists
missing_low = randint(2, length - 3)
missing_high = randint(missing_low + 2, length - 1)
# Assert that a column of length 0 will return an empty list
assert _generate_column([], 0) == []
# Randomized list containing 1-1000000 with random number missing
column_one = _generate_column([missing_high], length)
assert len(column_one) == length
# Randomized list containing 1-1000000 with two random
# numbers missing, one being from column_one
column_two = _generate_column([missing_low, missing_high], length)
assert len(column_two) == length
# Randomized list containing 1-1000000 with both ends missing
column_three = _generate_column([1, 1000000], length)
assert len(column_three) == length
# Randomized list containing 1-1000000 with two consecutive numbers missing
column_four = _generate_column([12346, 12345], length)
assert len(column_four) == length
# Write lists to 1000000 x 2 headerless csv file mock
csv_mock = _write_to_csv_mock(column_one, column_two)
assert isinstance(csv_mock, str)
if __name__ == "__main__":
unittest.main()
Now that we have created our testing arrays and mock CSV file object we can write some test cases for our challenge functions, defining how they should handle data and what our expected results should be. Doing this before writing the function logic itself will help us design our functions more clearly and ensure that the code works as expected. It also will allow us to easily test our functions when iteratively developing, debugging, or refactoring the code.
The test cases for the _pd_read_and_sort() and _read_and_sort() functions will make sure the mock CSV file is read, and that it produces two arrays, each of length 1000000.
@patch("builtins.open", mock_open(read_data=csv_mock))
def test_pd_read_and_sort(self) -> None:
"""Test _pd_read_and_sort function."""
columns = _pd_read_and_sort("test.csv")
self.assertEqual(len(columns), 2)
self.assertEqual(len(columns[0]), self.length)
self.assertEqual(len(columns[1]), self.length)
@patch("builtins.open", mock_open(read_data=csv_mock))
def test_read_and_sort(self) -> None:
"""Test _read_and_sort function."""
columns = _read_and_sort("test.csv")
self.assertEqual(len(columns), 2)
self.assertEqual(len(columns[0]), self.length)
self.assertEqual(len(columns[1]), self.length)
The test case for our _missing_from_list() function will make sure the function returns the values missing from the sorted input array. Our tests will include arrays with randomly chosen missing values, missing first and last values, consecutive missing values, and where there are no missing values at all.
def test_missing_from_list(self) -> None:
"""Test _missing_from_list function."""
missing_column_one = _missing_from_list(sorted(self.column_one))
missing_column_two = _missing_from_list(sorted(self.column_two))
missing_ends = _missing_from_list(sorted(self.column_three))
missing_consecutive = _missing_from_list(sorted(self.column_four))
missing_column_one_and_two = [
i for i in missing_column_two if i in missing_column_one
]
self.assertEqual(missing_column_one, [self.missing_high])
self.assertEqual(missing_column_two,
[self.missing_low, self.missing_high])
self.assertEqual(missing_column_one_and_two, [self.missing_high])
self.assertEqual(missing_ends, [1, 1000000])
self.assertEqual(missing_consecutive, [12345, 12346])
self.assertEqual(_missing_from_list([1, 2, 3, 4, 5]), [])
Finally we can write a test case for our solution() function, ensuring it returns the correct results when ran.
@patch("builtins.open", mock_open(read_data=csv_mock))
def test_solution(self) -> None:
"""Test solution function."""
self.assertEqual(solution("test.csv"),
[self.missing_high, self.missing_high])
When we run our test module with the unittest command-line interface, we can see that all our tests have completed, signaling that our test code is performing as we intended. As expected, all our tests have failed because we have not yet written the logic for the functions we are testing.
$ python -m unittest -v test.py
test_missing_from_list (test.UnitTestModule)
Test _missing_from_list function. ... FAIL
test_pd_read_and_sort (test.UnitTestModule)
Test _pd_read_and_sort function. ... FAIL
test_read_and_sort (test.UnitTestModule)
Test _read_and_sort function. ... FAIL
test_solution (test.UnitTestModule)
Test solution function. ... FAIL
======================================================================
...
...
...
----------------------------------------------------------------------
Ran 4 tests in 1.277s
FAILED (failures=4)
Challenge Function Logic
Now that we have some good tests for our challenge functions, we can write the actual function logic. Using TDD, writing our testable functions will be an iterative process. We first write the simplest code that will pass our tests, then refactor to improve the code and re-run the tests, fixing any issues or bugs that pop up while refactoring. We repeat this process as many times as needed until we are satisfied with our component logic. All of the code written below is the result of this iterative process and we will be seeing the final product of this process.
Let’s first write the logic for our two read and sort functions. These functions will read in the CSV file data, extract the column values and write them as integer types to separate arrays, replacing the empty string literals with the integer value 0. This will allow us to easily run sorting algorithms on all of the values, placing the former empty strings at the beginning of the arrays.
"""challenge.py"""
import csv
from typing import List, Any
import pandas as pd
def _pd_read_and_sort(file_name: str) -> List[List[int]]:
"""Given a csv file containing unlabeled columns of
unique numbers as strings, returns an array containing
arrays of each column sorted in ascending order as
integers with any empty or missing elements replaced
with 0s in the first positions.
Uses the Quicksort sorting algorithm for each column:
Time=O(n log(n)), Space=O(log (n))
Parameters
----------
arg1 : str
path/filename of csv file
Returns
-------
list of list of int
array containing arrays of sorted int values
Example
--------
>>> from io import StringIO
>>> test_csv = StringIO('"1","4"\\n"",""\\n"3","6"')
>>> _pd_read_and_sort(test_csv)
[[0, 1, 3], [0, 4, 6]]
"""
return_columns = []
data_frame = pd.read_csv(file_name, header=None)
for col in range(data_frame.shape[1]):
column: Any = data_frame.columns[col]
data_frame.sort_values(by=column, inplace=True, na_position="first")
return_columns.append(
data_frame[column].fillna(0).astype(int).tolist())
return return_columns
def _read_and_sort(file_name: str) -> List[List[int]]:
"""Given a csv file containing unlabeled columns of
unique numbers as strings, returns an array containing
arrays of each column sorted in ascending order as
integers with any empty or missing elements replaced
with 0 in the first positions.
Uses the Timsort sorting algorithm for each column:
Time=O(n log(n)), Space=O(n)
Parameters
----------
arg1 : str
path/filename of csv file
Returns
-------
list of list of int
array containing arrays of sorted int values
Example
--------
>>> from io import StringIO
>>> test_csv = StringIO('"1","4"\\n"",""\\n"3","6"')
>>> _pd_read_and_sort(test_csv)
[[0, 1, 3], [0, 4, 6]]
"""
return_columns = []
with open(file_name, "r", encoding="utf-8") as csv_file:
reader = csv.reader(csv_file)
csv_list = list(reader)
for col in range(len(csv_list[0])):
column = [0 if row[col] == "" else int(row[col]) for row in csv_list]
column.sort()
return_columns.append(column)
return return_columns
Now let’s test our updated functions by running the unittest CLI on their test cases.
$ python -m unittest test.UnitTestModule.test_pd_read_and_sort \
> test.UnitTestModule.test_read_and_sort -v
test_pd_read_and_sort (test.UnitTestModule)
Test _pd_read_and_sort function. ... ok
test_read_and_sort (test.UnitTestModule)
Test _read_and_sort function. ... ok
----------------------------------------------------------------------
Ran 2 tests in 3.639s
OK
All tests passed and everything looks good. We can now write our _missing_from_list() function logic. In this function we will count the number of 0s at the beginning of the array, as this will give us a count on how many values are missing. Then we will use that as a counter and loop a binary search algorithm over the array until we find all of the missing values, breaking out of the loop and returning the values we found.
def _missing_from_list(input_list: List[int]) -> List[int]:
"""Given an array of ascending sorted integers,
starting at the first non-zero integer, returns a
sorted array containing all missing sequential integers
from the input array using a looped binary search
algorithm.
Parameters
----------
arg1 : list of int
array of sorted int values
Returns
-------
list of int
array of sorted ints missing from the input array
Example
-------
>>> _missing_from_list([0, 0, 1, 2, 3, 5, 6, 8, 9])
[4, 7]
>>> _missing_from_list([1, 2, 3, 4, 5, 6, 7, 8, 9])
[]
"""
missing: List[int] = []
count = 0
for i in input_list:
if not i:
count += 1
else:
break
for i in range(count):
input_list.pop(0)
if input_list[0] != 1:
input_list.insert(0, 1)
missing.append(1)
while len(missing) != count:
low = 0
high = len(input_list)
while low < high:
mid = (low + high) // 2
if input_list[mid] > mid + 1:
high = mid
else:
low = mid + 1
if len(missing) == count - 1 and mid + 1 == high:
input_list.insert(high, high + 1)
missing.append(high + 1)
break
value = input_list[low] - 1
index = value - 2 if value < input_list[value - 2] else value - 1
input_list.insert(index, value)
missing.append(value)
missing.sort()
return missing
When we run our test case on this updated function we can see that everything works as expected.
$ python -m unittest test.UnitTestModule.test_missing_from_list -v
test_missing_from_list (test.UnitTestModule)
Test _missing_from_list function. ... ok
----------------------------------------------------------------------
Ran 1 test in 1.214s
OK
In our solution() function we can call the _pd_read_and_sort() function with the CSV filename argument passed through to it, generating our two sorted arrays, then call _missing_from_list() on the second array to obtain it’s missing values. We can then find the missing value from the column one array by looping over the values that are missing from the column two array, using it’s values plus a negative counter offset as the index for the first array and comparing the two. If the value at the column one array index does not match the missing number from column two, the number is missing from column one and we appended it to our result array. This solves the first part of the interview question.
For the second part, we will just independently run the _missing_from_list() function on the first column array and append the resulting value to the result array. Doing this is potentially slower than how we obtained the result in the first part of the question, as now we have to run a binary search over the entire column array instead of just checking via index using known missing values from the column two array. It is much easier to find the missing value from column one if we know that value is also missing from column two. But since the question was split into two parts, I decided we should separate the logic for them.
def solution(csv_file: str) -> List[int]:
"""Given a headerless csv file
with two equal length columns of
integers in range 1 to (inf - 1) as
string literals, and empty string
literals in place of missing values,
returns an array of integers where the
first value is missing from both
columns and the second value is
missing from the first column.
Parameters
----------
arg1 : str
path/filename of csv file
Returns
-------
list of int
array containing int values missing from
both columns in input csv file
Example
-------
>>> from io import StringIO
>>> test_csv = StringIO('"3","4"\\n"1",""\\n"",""\\n"4","1"')
>>> solution(test_csv)
[2, 2]
"""
result = []
columns = _pd_read_and_sort(csv_file)
# Part 1: Find the number that is missing from both columns
missing_from_column_two = _missing_from_list(columns[1])
count = 0
for num in missing_from_column_two:
if num != columns[0][num + count]:
result.append(num)
count -= 1
# Part 2: Find the number missing in the first column
missing_from_column_one = _missing_from_list(columns[0])
result += missing_from_column_one
return result
Our solution() function passes it’s test.
$ python -m unittest test.UnitTestModule.test_solution -v
test_solution (test.UnitTestModule)
Test solution function. ... ok
----------------------------------------------------------------------
Ran 1 test in 0.751s
OK
Finally, we will run our entire test module to make sure everything executes and passes.
$ python -m unittest -v test.py
test_missing_from_list (test.UnitTestModule)
Test _missing_from_list function. ... ok
test_pd_read_and_sort (test.UnitTestModule)
Test _pd_read_and_sort function. ... ok
test_read_and_sort (test.UnitTestModule)
Test _read_and_sort function. ... ok
test_solution (test.UnitTestModule)
Test solution function. ... ok
----------------------------------------------------------------------
Ran 4 tests in 5.826s
OK
At this point we are pretty much finished. We can always go back and refactor our code to optimize it or increase readability/visibility/maintainability, re-run our tests and repeat the process as necessary. As it stands I am fairly happy with the code we have written. Our solution() function will solve the interview problem successfully with acceptable time/space complexity.
More Testing
Additional things we can do to increase and enforce testing thoroughness and code quality standards are to add python doctests, flake8 linting checks, mypy static type checking, and testing code coverage reporting. We can package all of these tests into a simple shell script.
First, let’s create a requirements.txt file including all the packages and dependencies we will need for our module and testing.
flake8==4.0.1
mypy==0.961
mypy-extensions==0.4.3
pandas==1.4.3
pandas-stubs==1.4.3.220718
coverage>=6.4.2
Now we can write a simple bash script, test.sh, to install the dependencies, run our tests, and print out our code coverage report.
#!/bin/sh
# Upgrade pip and install dependencies
echo "\n----------------------------------------------------------------------"
echo "\nInstalling Python Dependencies:\n"
python --version
pip install --upgrade pip
pip install -r requirements.txt
echo "\n----------------------------------------------------------------------"
# Lint with flake8
echo "\nPerforming Linting and Syntax Checks:\n"
# stop the build if there are Python syntax errors or undefined names
flake8 . --count --select=E9,F63,F7,F82 --show-source --statistics
# exit-zero treats all errors as warnings
flake8 . --count --exit-zero --max-complexity=10 --max-line-length=127 --statistics
echo "\n----------------------------------------------------------------------"
# Static type checking with mypy
echo "\nPerforming Static Type Analysis:\n"
python -m mypy --strict .
echo "\n----------------------------------------------------------------------"
# Doctests
echo "\nPerforming Python Doctests:\n"
python -m doctest -f -v *.py
echo "\n----------------------------------------------------------------------"
# Unit tests and code coverage reporting
echo "\nPerforming Unit Tests:\n"
python -m coverage run test.py -v
echo "\n----------------------------------------------------------------------"
echo "\nGenerating Code Coverage Report:\n"
python -m coverage lcov -o ./coverage/lcov.infoa
python -m coverage html
echo "\n"
python -m coverage report
echo "\n----------------------------------------------------------------------\n"
Now we can execute test.sh and run all of our tests.
$ ./test.sh
----------------------------------------------------------------------
Installing Python Dependencies:
Python 3.8.0
Requirement already satisfied: pip in .../site-packages (22.2.1)
Requirement already satisfied: flake8==4.0.1 in ...
Requirement already satisfied: mypy==0.961 in ...
Requirement already satisfied: mypy-extensions==0.4.3 in ...
Requirement already satisfied: pandas==1.4.3 in ...
Requirement already satisfied: pandas-stubs==1.4.3.220718 in ...
Requirement already satisfied: coverage>=6.4.2 in ...
Requirement already satisfied: mccabe<0.7.0,>=0.6.0 in ...
Requirement already satisfied: pyflakes<2.5.0,>=2.4.0 in ...
Requirement already satisfied: pycodestyle<2.9.0,>=2.8.0 in ...
Requirement already satisfied: tomli>=1.1.0 in ...
Requirement already satisfied: typing-extensions>=3.10 in ...
Requirement already satisfied: pytz>=2020.1 in ...
Requirement already satisfied: python-dateutil>=2.8.1 in ...
Requirement already satisfied: numpy>=1.18.5 in ...
Requirement already satisfied: types-pytz>=2022.1.1 in ...
Requirement already satisfied: six>=1.5 in ...
----------------------------------------------------------------------
Performing Linting and Syntax Checks:
0
0
----------------------------------------------------------------------
Performing Static Type Analysis:
Success: no issues found in 2 source files
----------------------------------------------------------------------
Performing Python Doctests:
...
...
...
1 items had no tests:
challenge
4 items passed all tests:
2 tests in challenge._missing_from_list
3 tests in challenge._pd_read_and_sort
3 tests in challenge._read_and_sort
3 tests in challenge.solution
11 tests in 5 items.
11 passed and 0 failed.
Test passed.
...
...
...
6 items had no tests:
test
test.UnitTestModule
test.UnitTestModule.test_missing_from_list
test.UnitTestModule.test_pd_read_and_sort
test.UnitTestModule.test_read_and_sort
test.UnitTestModule.test_solution
2 items passed all tests:
3 tests in test._generate_column
1 tests in test._write_to_csv_mock
4 tests in 8 items.
4 passed and 0 failed.
Test passed.
----------------------------------------------------------------------
Performing Unit Tests:
test_missing_from_list (__main__.UnitTestModule)
Test _missing_from_list function. ... ok
test_pd_read_and_sort (__main__.UnitTestModule)
Test _pd_read_and_sort function. ... ok
test_read_and_sort (__main__.UnitTestModule)
Test _read_and_sort function. ... ok
test_solution (__main__.UnitTestModule)
Test solution function. ... ok
----------------------------------------------------------------------
Ran 4 tests in 5.828s
OK
----------------------------------------------------------------------
Generating Code Coverage Report:
Wrote LCOV report to ./coverage/lcov.infoa
Wrote HTML report to htmlcov/index.html
Name Stmts Miss Cover
----------------------------------
challenge.py 63 0 100%
test.py 70 0 100%
----------------------------------
TOTAL 133 0 100%
----------------------------------------------------------------------
Our code has passed all tests and we have 100% testing coverage.